While it's possible that there is a minor speed overhead in practice it depends a lot on the implemention use of the string API. A real string API will often work well in the weird corner cases as well. Note that in the above the original "fast" C string style version had 4 security flaws and was about 2.0 times slower than the Vstr version, the hand optimized goto based version was about 0.7 of the Vstr speed ... but if you needed it to be that fast, I'm sure the Vstr version would be very close if you used the same "design". However, saying all that, I have done some "theoretical" benchmarks...
The thing to understand is that Vstr is designed for use cases where you have N connections to the internet, and are getting/sending data to M of them in a non-blocking fashion at once. In this case Vstr can share all the spare/cached memory in the configuration among just the M connections, while having close to zero memory allocated for the M-N connections that aren't active. Whereas a normal buffer based API often just has N * BUFFER_SIZE, always allocated.
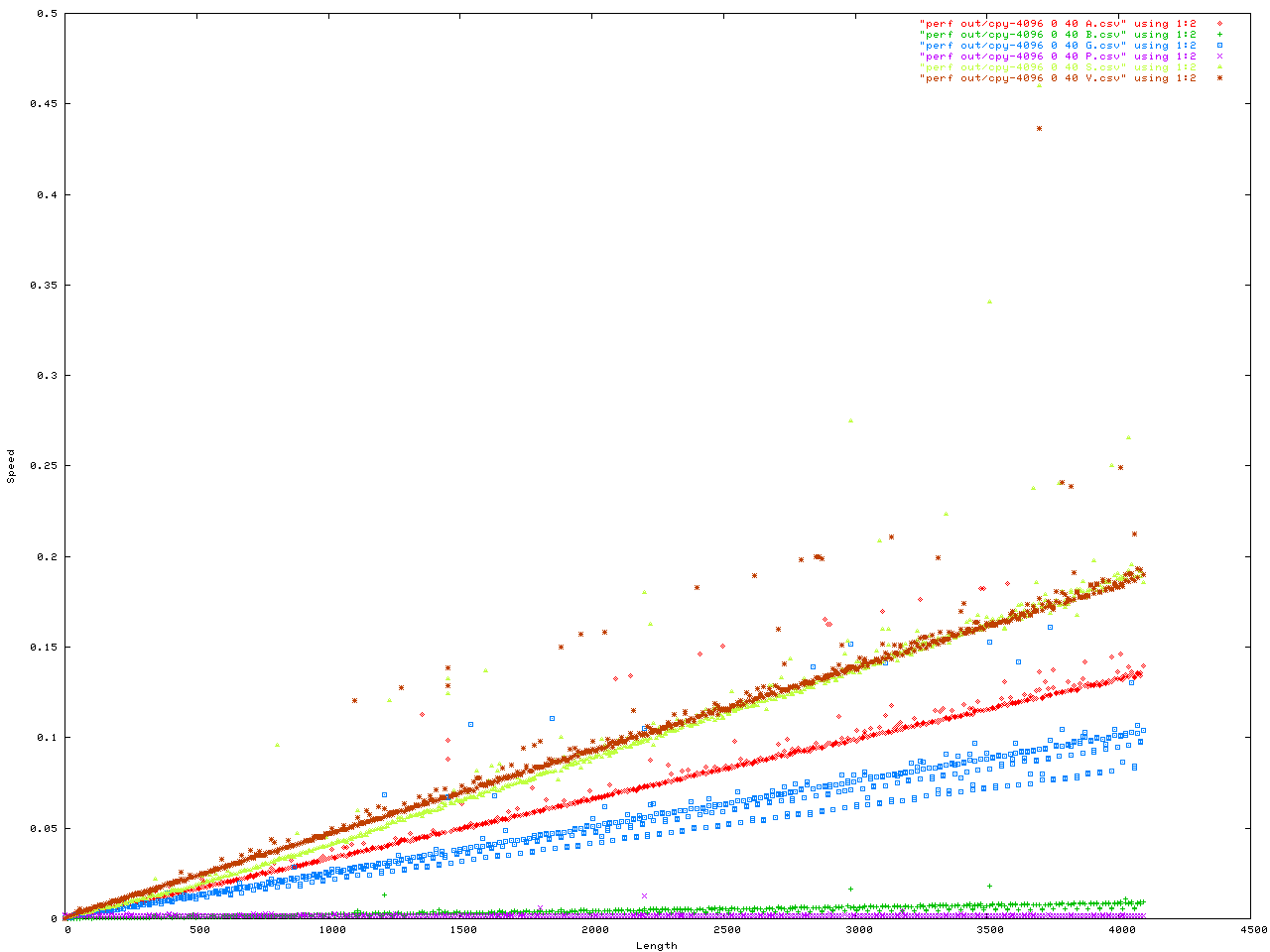
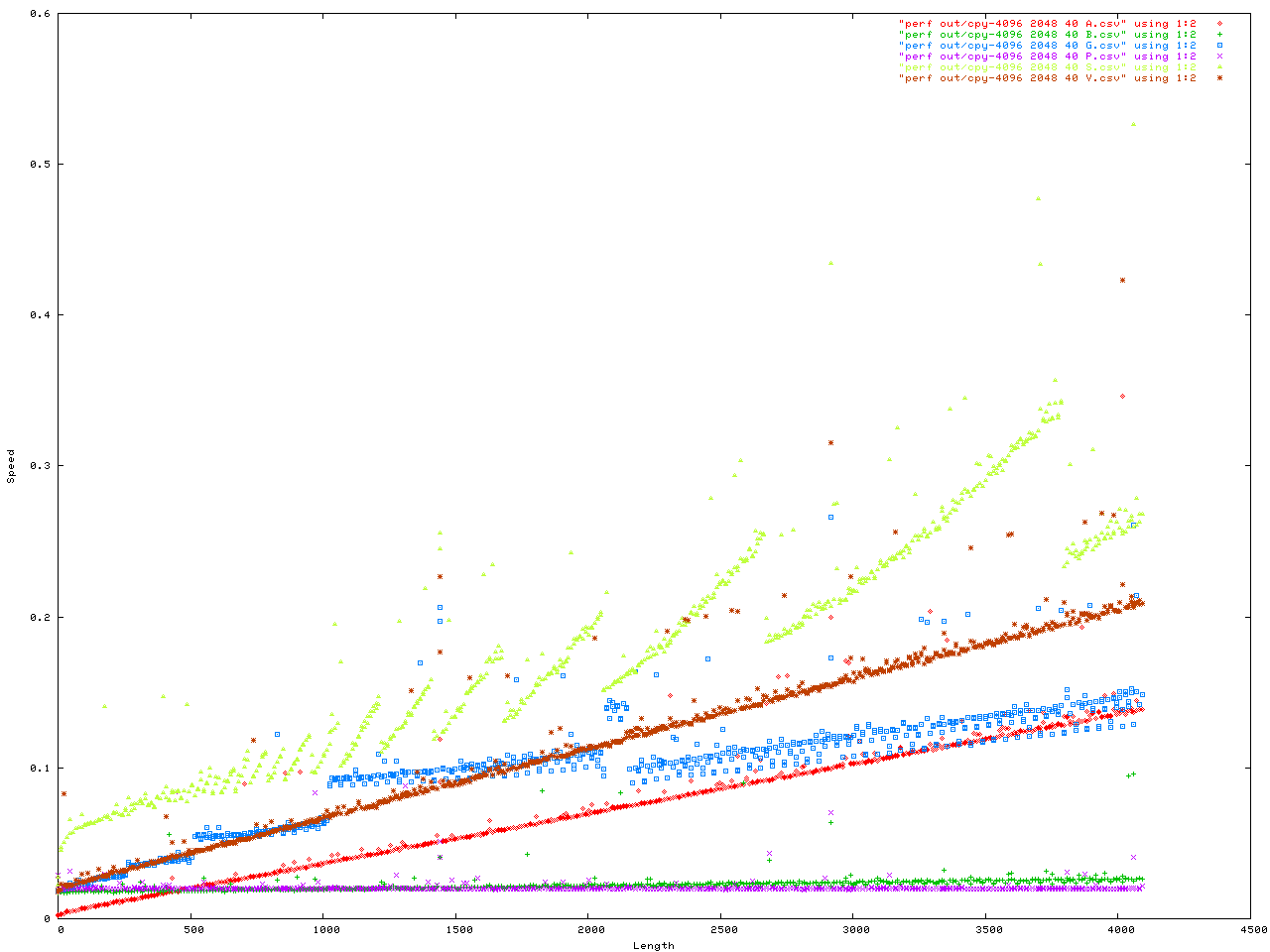
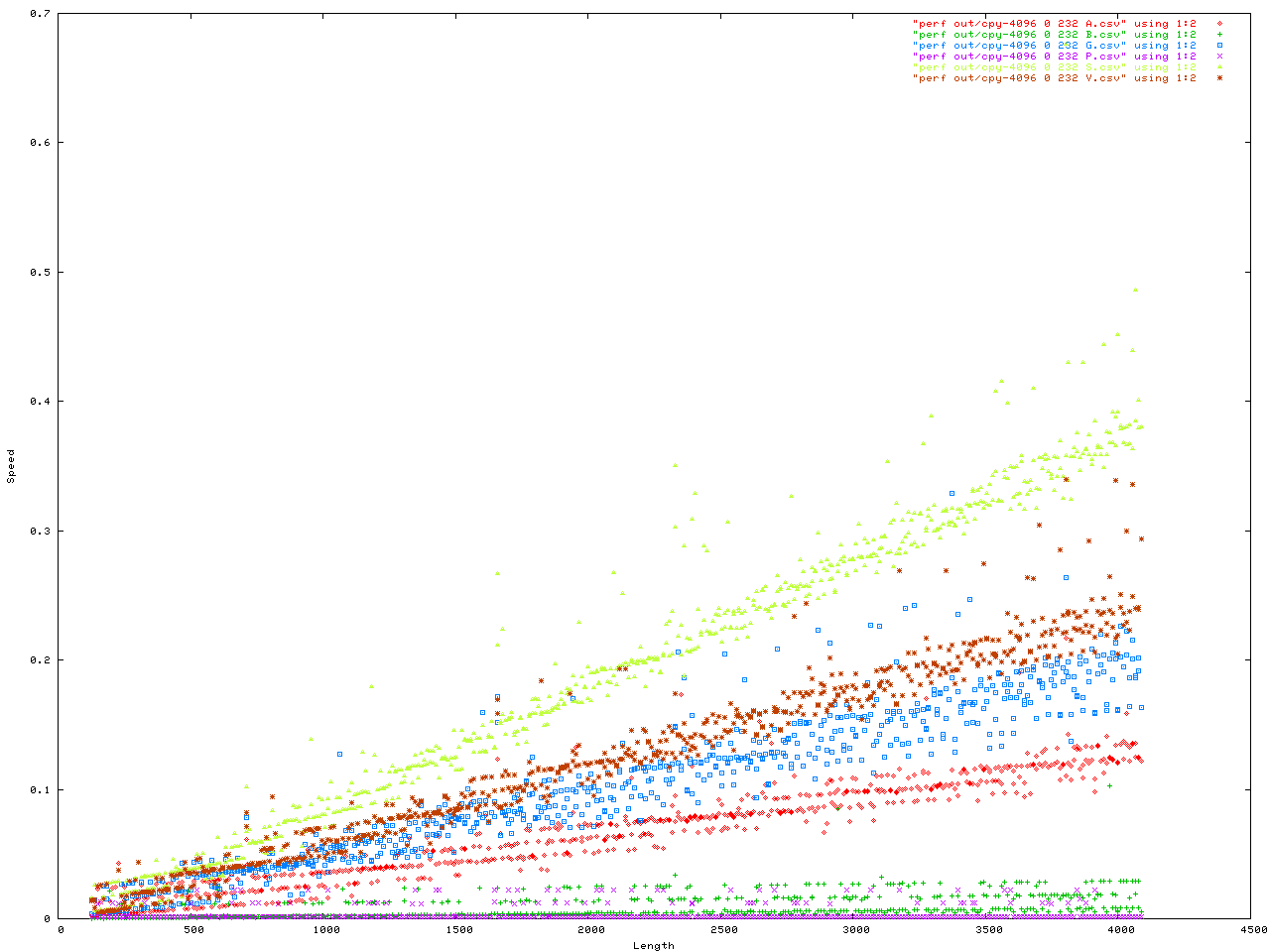
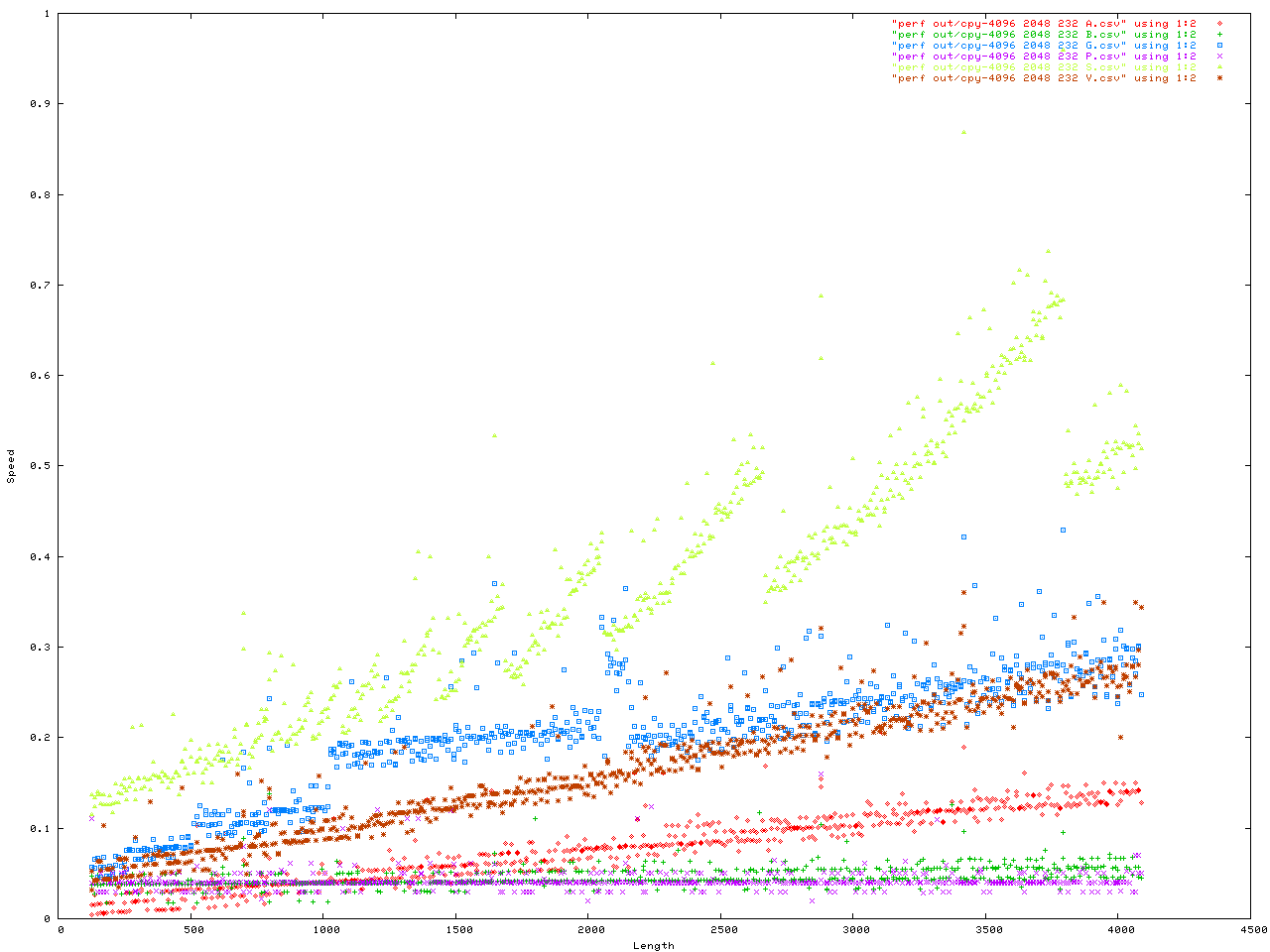
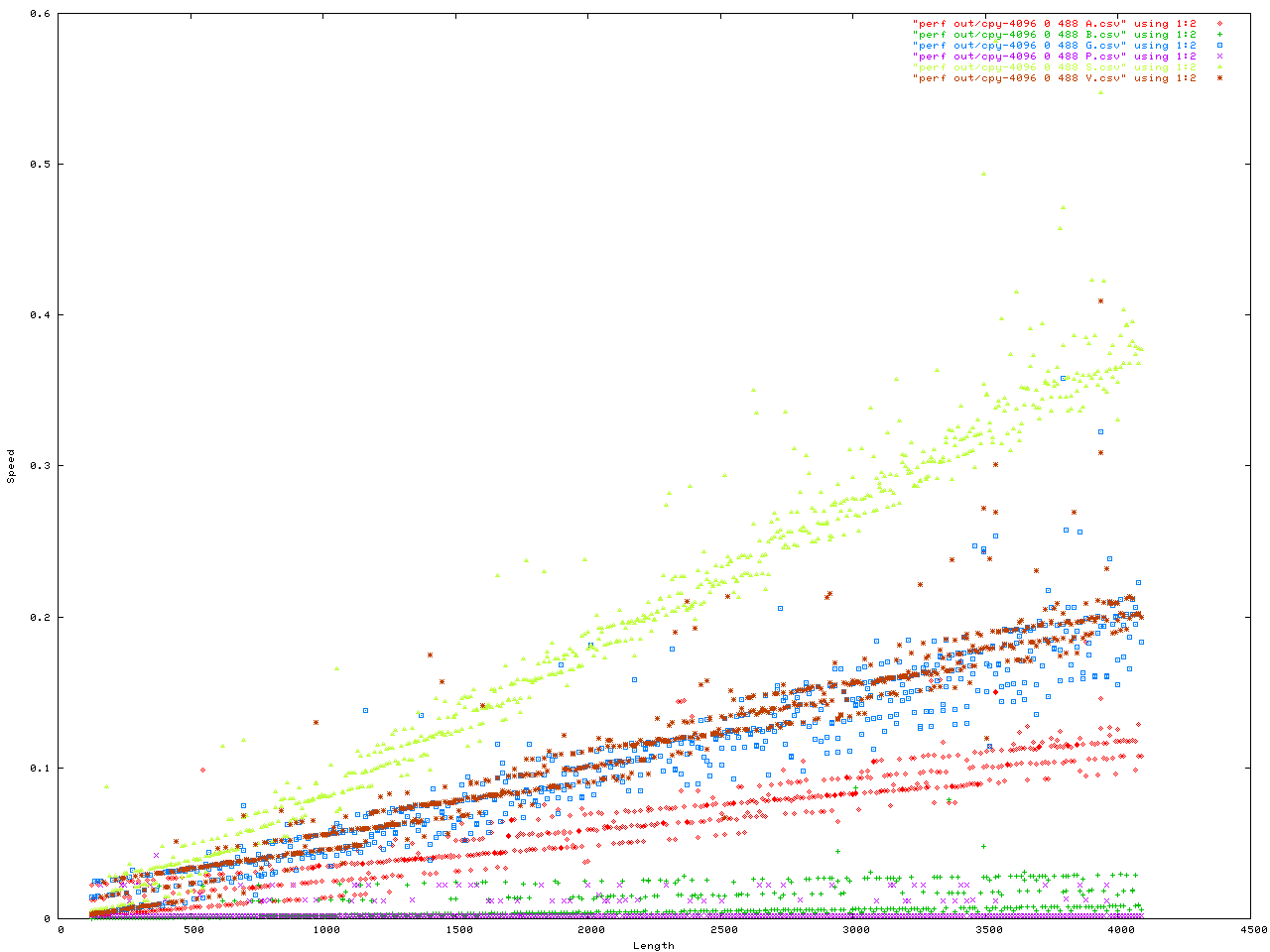
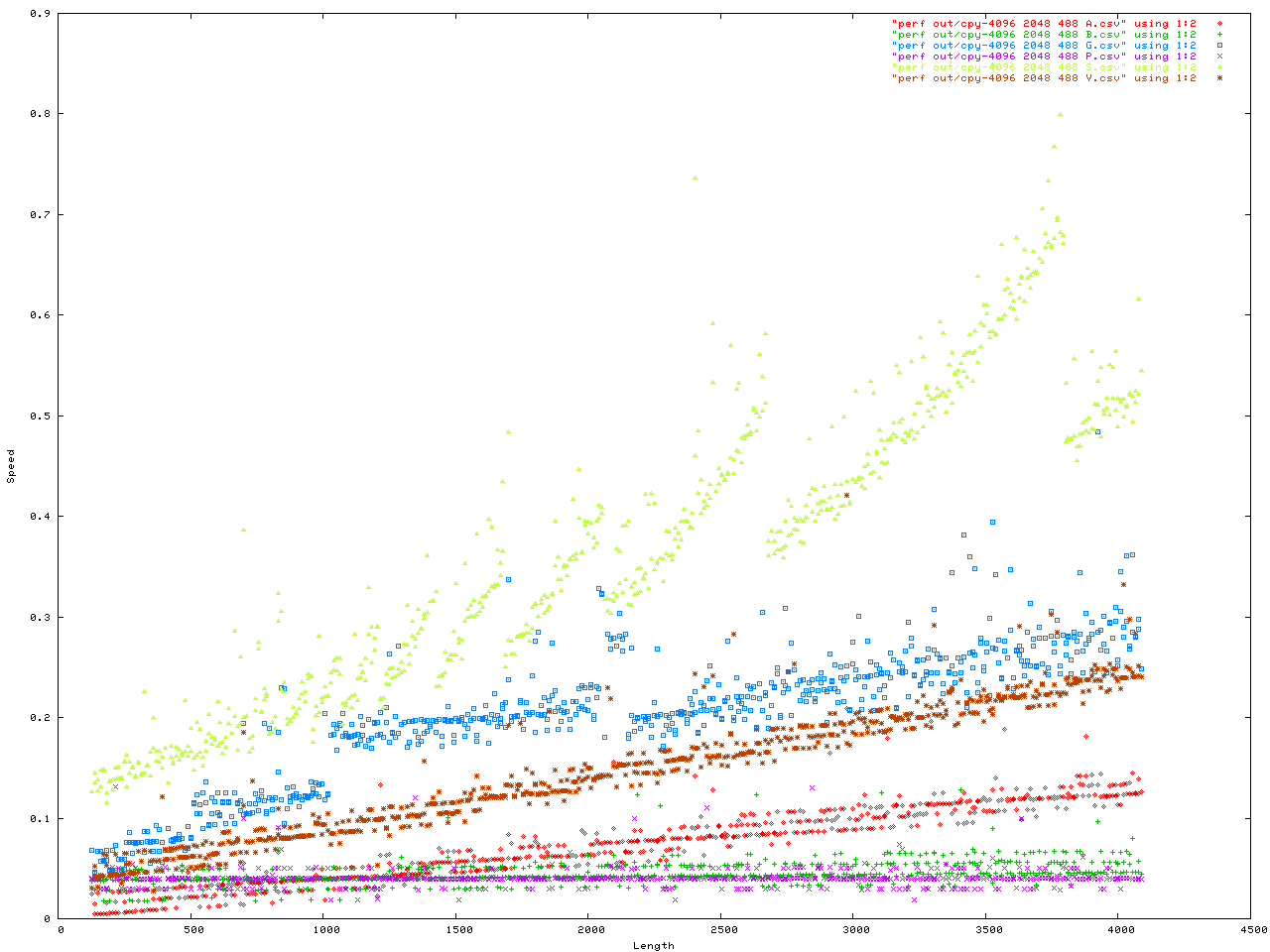
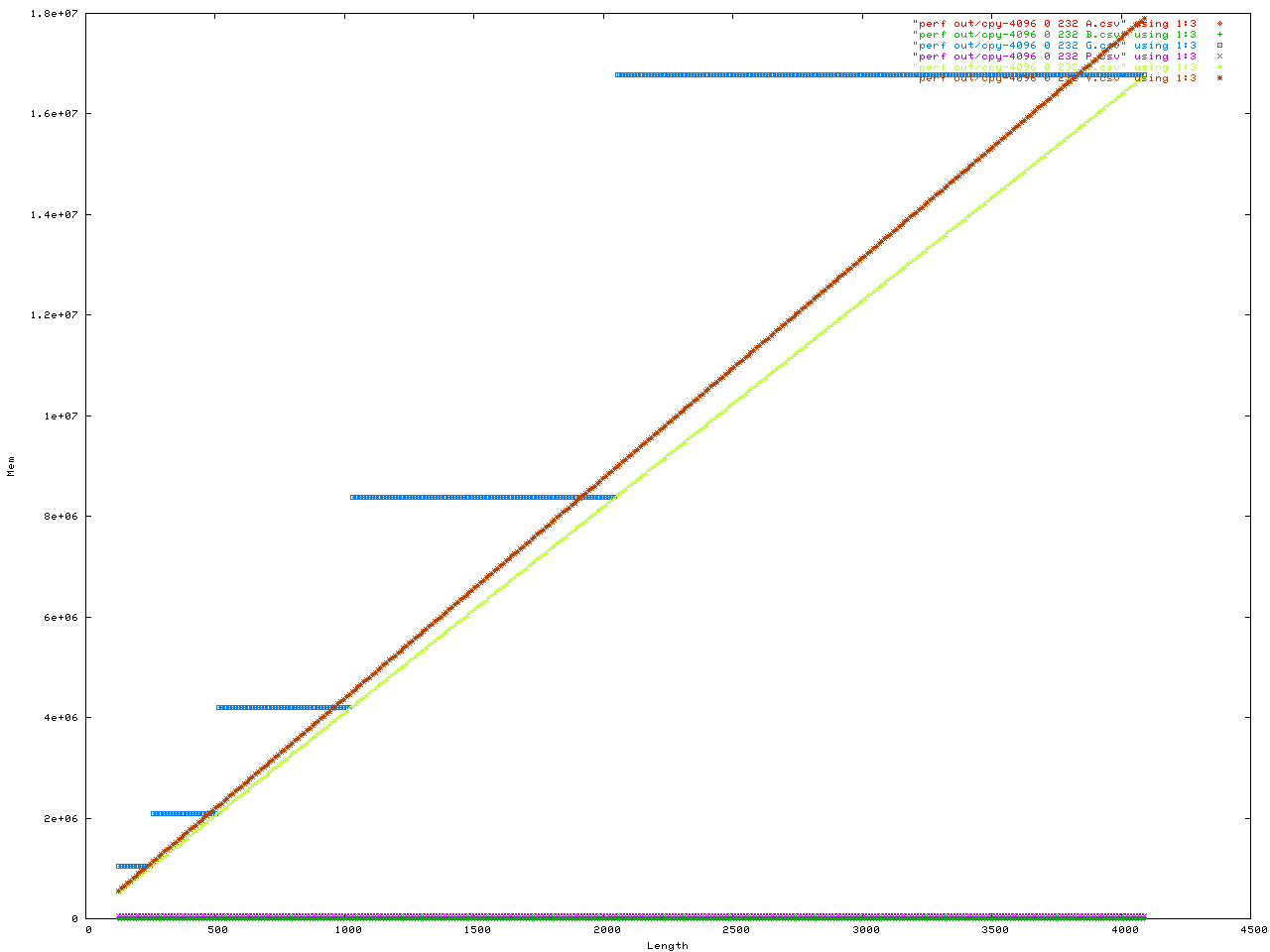
Anyway here are the benchmarks. This was a benchmark to measure how fast memory is moved into the string API. They were configured in a number of ways. First is the size of each _BUF node in the Vstr, second is the "extra" ammount of malloc() activity, all iteractions were done with number of iteractions = 4096 and each config. was done twice in case one got a weird result for some reason. Here is the code for the benchmark, and here is the header.
The X axis is always the length to be added to the string API. The y axis is either the time in seconds, or the memory used.
You can get the data files for the above, and more, here. For format of the file is <length> <speed> <memory used> <unused memory>. You can plot this in gnuplot by doing...
# Using the data files with 0 extra memory allocations per call,
# and 488 _BUF siazed nodes...
# Plot memory usage...
set xlabel "Length"
set ylabel "Mem"
plot "cpy-4096_0_488_A.csv" using 1:3, \
"cpy-4096_0_488_B.csv" using 1:3, \
"cpy-4096_0_488_G.csv" using 1:3, \
"cpy-4096_0_488_P.csv" using 1:3, \
"cpy-4096_0_488_S.csv" using 1:3, \
"cpy-4096_0_488_V.csv" using 1:3
# Plot speed...
set xlabel "Length"
set ylabel "Speed"
plot "cpy-4096_0_488_A.csv" using 1:2, \
"cpy-4096_0_488_B.csv" using 1:2, \
"cpy-4096_0_488_G.csv" using 1:2, \
"cpy-4096_0_488_P.csv" using 1:2, \
"cpy-4096_0_488_S.csv" using 1:2, \
"cpy-4096_0_488_V.csv" using 1:2
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}